The Schema Is the Product’s Memory: Why Database Design Shapes What Your App Can Become
A database does not simply store information. It remembers the world in a particular way.
That sounds dramatic until you have to change a real product.
A customer asks why they cannot transfer ownership of a project. The answer is not in the button. It is in the schema. A finance team wants to see the price a customer actually paid six months ago. The answer is not in the dashboard. It is in the schema. A founder wants to add teams, permissions, invoices, subscriptions, locations, audit logs, refunds, and custom fields. Again, the answer is usually not “we need one more page.” It is “what did we assume when we designed the data?”
This is the part of database design that beginners often miss and experienced teams eventually respect: a schema is not neutral. It carries assumptions about identity, ownership, time, meaning, and responsibility. Once those assumptions are baked into tables and relationships, the application starts inheriting them.
Good schema design is not about drawing a tidy diagram. It is about deciding what your system is allowed to remember, what it is allowed to forget, and what it can still understand when the business changes.
A Schema Is a Set of Promises
Every database table makes a promise.
A users table promises that a person can be represented as a user account. A projects table promises that a project is a thing with its own identity. A user_id inside projects quietly promises that each project belongs to one user.
That last promise may feel harmless at first. In a small app, it may even be true. One user creates one project. Simple.
Then the product grows.
A company asks for shared access. A manager wants to assign projects to employees. A contractor needs temporary access. A customer wants to transfer a project to another account. Someone asks for an audit trail showing who created the project, who owns it now, and who last edited it.
Suddenly, the original design is no longer a simple relationship. It is a business rule pretending to be a column.
This is where many schema problems begin. The database did not just store the data. It stored a belief: “a project has one owner, and that owner is a user.” When the product stops believing that, the schema starts resisting the product.
The Hidden Cost of Modeling the Wrong Relationship
Weak database design rarely fails all at once. It usually fails through small inconveniences that slowly become expensive.
Imagine a booking platform. The first version has customers, rooms, and bookings. A booking has a room_id, a customer_id, a start date, and an end date. It looks reasonable.
Then reality arrives.
The customer changes rooms midway through the stay. A company books multiple rooms under one reservation. A guest is not the same person as the payer. A room goes out of service. A booking is cancelled, but the cancellation reason matters. A discount is applied after the booking is created. The original room rate must still be visible later, even if the room’s default price changes.
If the schema treats “booking” as a single flat object, the application becomes a mess of exceptions. Developers start adding columns such as secondary_room_id, changed_room, original_price, override_price, cancelled_by_admin, and special_case_note. Each new column solves one problem while making the whole model harder to trust.
The deeper issue is not that the first schema was too small. It modeled the wrong relationship. A booking was not merely a customer connected to a room. It was an agreement, possibly involving multiple guests, payments, room assignments, price snapshots, status changes, and events over time.
That does not mean every early design needs enterprise complexity. It means designers should ask a sharper question: “Is this relationship stable, or is it hiding a process?”
Reframing the Common Assumption: Tables Are Not Just Things
A common way to introduce database design is to say that tables represent “things” or “entities.” That is useful, but incomplete.
Some tables represent things. Some represent relationships. Some represent decisions. Some represent events. Some represent the state of something at a moment in time.
This distinction changes how you design.
A product’s current price may belong in a products table. But the price a customer paid should probably live somewhere else, such as an order_items table. Why? Because it is no longer just a product attribute. It is part of a historical transaction.
A user’s current email address may live on the user record. But if your system needs to know where password reset emails were sent last year, you may need email history. A subscription’s current plan may be a column. But if billing, support, or analytics need to understand upgrades and downgrades, plan changes become events.
So the better question is not “what are the entities?”
The better question is: “What kind of truth is this?”
- State: What is true right now?
- History: What used to be true?
- Ownership: Who controls or is responsible for this?
- Event: What happened, when, and because of whom?
- Agreement: What terms were accepted at a specific moment?
- Snapshot: What did the system believe at the time?
Many painful schema redesigns happen because state, history, and events were mixed together as if they were the same kind of data.
ER Diagrams Should Expose Arguments, Not Hide Them
ER diagrams are often treated like documentation artifacts: boxes, lines, labels, export, done. But their real value is not the final picture. Their value is the conversation they force.
When you draw a line between customers and orders, you are not just drawing a relationship. You are asking:
- Can one customer have many orders?
- Can an order exist without a customer?
- Can a customer be deleted if orders exist?
- Can an order belong to a company instead of a person?
- Is the customer the buyer, recipient, account owner, or billing contact?
Those questions are not academic. They determine how the product behaves under pressure.
A useful ER diagram should make ambiguity visible. If nobody argues with the diagram, it may be because the diagram is obvious. Or it may be because it is too vague to reveal the hard parts.
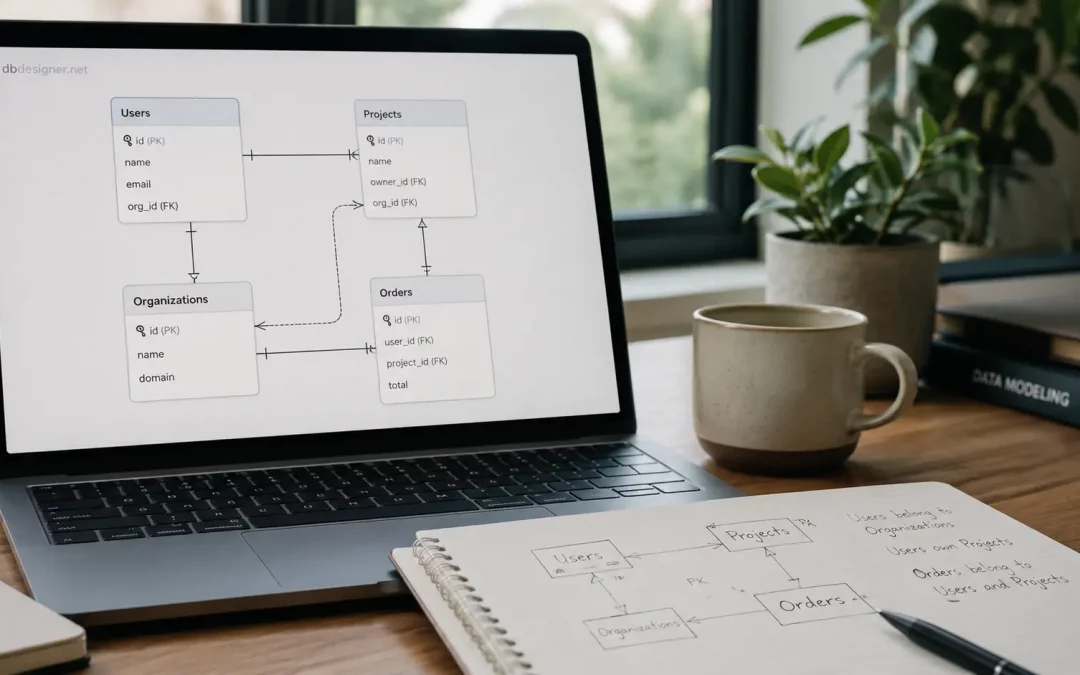
Tools such as DBDesigner can help teams map tables and relationships visually, while erd.dbdesigner.net is useful when you want to quickly reason through ER diagrams without turning the discussion into a heavy documentation process. The point is not the tool itself. The point is to make hidden assumptions visible before they become migrations, bugs, and awkward product limitations.
The Dangerous Comfort of “Just Add a Column”
Few phrases are more tempting in software than “just add a column.”
Sometimes that is exactly right. A missing birthdate, a display preference, a shipping instruction, a published flag—many features deserve a simple column.
But “just add a column” becomes dangerous when the new data represents a new concept rather than a new attribute.
Suppose you run a marketplace. A seller can be “verified.” At first, you add is_verified to the sellers table. Simple.
Then verification gets more serious. There are verification levels. Some expire. Some require documents. Some are reviewed by staff. Some fail. Some are revoked. Support wants to know why. Legal wants to know when. Analytics wants to compare conversion rates by verification status.
Now is_verified is no longer a harmless boolean. It is a collapsed workflow.
A stronger design might include seller_verifications, with status, submitted date, reviewed date, reviewer, evidence, expiration, and reason fields. That may feel heavier, but it matches the reality better. The schema is no longer pretending that verification is a simple on/off fact. It recognizes verification as a process with memory.
The practical test is this: if people keep asking “when,” “why,” “who changed it,” or “what happened before,” you may not be dealing with a column. You may be dealing with an event or lifecycle.
Weak Schemas Create Product Problems That Look Like UX Problems
Bad schema choices often surface as strange user experiences.
A user cannot belong to two organizations, so they create two accounts. That looks like an onboarding issue, but it is a data model issue.
A customer cannot change their billing contact without changing account ownership. That looks like a settings page issue, but it is a relationship issue.
A report cannot show historical revenue correctly because old orders point to current product prices. That looks like an analytics issue, but it is a snapshot issue.
A support agent cannot explain why a subscription changed because only the current plan is stored. That looks like a support tooling issue, but it is a missing history issue.
When applications feel rigid, confusing, or inconsistent, the interface is not always the root cause. Often the UI is simply exposing the limits of the schema underneath it.
This is why database design deserves attention before the product feels “big enough” to need it. A schema does not need to predict every future feature, but it should avoid trapping the product inside assumptions that are already fragile.
Design for the Questions the Business Will Ask Later
One of the most useful schema design habits is imagining future questions.
Not imaginary features. Questions.
For an e-commerce system, the future questions might be:
- What did the customer pay at the time of purchase?
- Which promotion influenced the order?
- Was this item refunded, replaced, cancelled, or fulfilled?
- Who changed the shipping address?
- Which supplier provided the item?
For a SaaS product, they might be:
- Who invited this user?
- Which organization owns this workspace?
- What permissions did the user have when they performed this action?
- When did the account move from trial to paid?
- Which plan limits applied at the time?
These questions reveal where the schema needs memory. They also reveal where a simple relationship may not be enough.
This does not mean storing everything forever. That creates its own problems. It means being intentional. Some data is operational and can change freely. Some data is historical and must remain stable. Some data is evidence. Some data is convenience. Treating all of it the same is how systems lose meaning.
Boundaries Matter More Than Beautiful Diagrams
A clean diagram can still represent a confused system.
The hardest part of database design is often deciding where one concept ends and another begins. Is a “customer” the same as a “user”? Is an “account” the same as an “organization”? Is a “payment” the same as an “invoice”? Is a “member” a person, a role, or a relationship between a person and a workspace?
These naming decisions are not cosmetic. Names define boundaries. Boundaries shape relationships. Relationships determine what the system can express.
Consider the difference between these two designs:
Design A: A users table has a company_name column.
Design B: A users table connects to an organizations table through an organization_memberships table.
Design A is quicker. It may be perfectly fine for a simple contact form or solo-user tool.
Design B supports organizations with multiple users, roles, invitations, ownership transfer, team billing, and access control. It also makes the product’s assumptions clearer: a user is a person or login identity; an organization is a separate unit; membership is the relationship between them.
Neither design is universally correct. The better design depends on what reality the product needs to represent. But if the product is clearly about teams, Design A is not simple. It is delayed complexity.
A Practical Way to Review Your Schema
Before committing to a schema, walk through a few uncomfortable scenarios. Not edge cases for the sake of edge cases, but realistic moments when the business changes shape.
Ask:
- What happens if ownership changes?
- What happens if one person needs multiple roles?
- What happens if a value changes but old records must stay accurate?
- What happens if this process gains approval, rejection, or review steps?
- What happens if two concepts we merged today need to separate later?
- What happens if the business asks “who did this and when?”
These questions do not automatically mean you need more tables. Sometimes they confirm that your current model is enough. Other times they reveal that your schema is flattening something important.
The goal is not to make the database complicated. The goal is to put complexity where it belongs.
Good Database Design Feels Boring Later
The best schema decisions are often invisible. Months later, a new feature arrives and the data model has a natural place for it. A report needs historical accuracy and the right snapshot already exists. A user changes roles and the system does not collapse. A workflow gains a review step and the model can absorb it.
That kind of flexibility does not happen by accident.
It comes from seeing database design as representation, not storage. It comes from treating ER diagrams as thinking tools, not decorative documentation. It comes from noticing when a column is hiding a process, when a relationship is hiding a rule, and when a name is hiding two different meanings.
A schema is the memory of the product. It remembers what happened, what matters, who is connected to whom, and which truths are allowed to change.
Design it carelessly, and your application will spend years working around forgotten assumptions.
Design it thoughtfully, and the database becomes something quieter and more powerful: a structure that helps the product grow without losing its sense of reality.
Recent Comments